Can you spot the difference between these two images?
Original image:
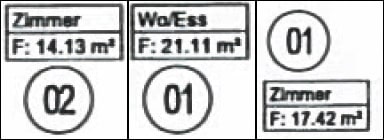
Scanned image:
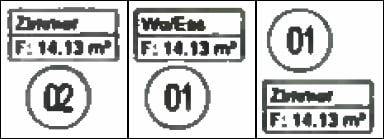
Of course, they’re not supposed to be pixel-for-pixel identical. The second is supposed to be a scan of the original done by a Xerox WorkCentre 7535, and the quality and resolution is far from perfect.
But what is surprising is that the scanner has changed some of the numbers.
Yup. Do you see how 21.11 m2 has become 14.13 m2… and 17.42m2 has become 14.13m2?
This problem was discovered by German computer scientist David Kriesel.
He became aware of the problem he scanned and reprinted a construction plan last week, only to be puzzled as to how one room on the plan was – according to the copy – about 22 m2 in size whereas the next much larger room was only said to be 14 m2.
Here’s a section of the construction plan (you can click on it for a larger version) with the areas in question highlighted in yellow.

Kriesel had scanned the production plan to make a PDF file from it. He wasn’t attempting to use OCR to extract the text from the plan, this was simply scanning an image. And yet, the Xerox WorkCentre clearly substituted incorrect numbers during the process.
This isn’t the wrong pixels being placed misleadingly in the image during the scanning process – this is the Xerox WorkCentre mixing up and copying segments of the image.
Imagine how costly this could be if it wasn’t noticed soon enough in the construction process. Or, as Krisel suggests even more seriously, just think of how lives could be put at risk if this was a mangled medical record containing a list of drug dosages.
Here’s another example David Kriesel discovered, when he scanned in a cost table:
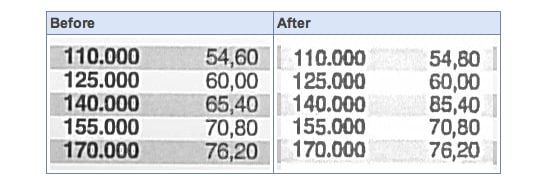
I think you’ll agree, that’s not good at all.
So what is causing all of this?
Well, it appears that the problem lies in the Xerox WorkCentre’s use of the JBIG2 algorithm to compress and decompress images.
 As Kriesel explains it, Xerox uses the algorithm to create a “dictionary of image patches found to be ‘similar’. Those patches then get reused instead of the original image data, as long as the error generated by them is not “too high'”.
As Kriesel explains it, Xerox uses the algorithm to create a “dictionary of image patches found to be ‘similar’. Those patches then get reused instead of the original image data, as long as the error generated by them is not “too high'”.
According to Xerox, the number-mangling only happens if users alter their scanner’s default settings from “high” quality to “normal”. Hmm.. I’d hardly call it “normal” to have terrible errors to be introduced into my documents just because I wanted a smaller PDF file. Nobody expects that.
Xerox, understandably, appears to have gone into crisis-mode over the revelations and has attempted to dampen the flames, telling the BBC that the vast majority of customers would never experience the problem.
So, who *would* turn on “normal” quality to get a smaller scanned file at the end of the process?
Well, according to Xerox vice president Rick Dastin who spoke to the BBC, nobody really important… just oil rigs… the military… companies in developing countries…

… hang on a minute! Oil rigs and the military!? Isn’t it rather important that they get their numbers right?
Xerox says it is developing a patch which will be able to disable the offending option on their WorkCentre devices.
In the meantime, be careful to check anything that you scan, and perhaps read more of David Kriesel’s fascinating exploration into the issue.


